PostgreSQL Shared Buffer 1 (Hash Table, Hash Element)
[PostgreSQL]PostgreSQL Shared Buffer 1
Shared Buffer
Shared Buffer은 데이터 페이지를 메모리에 캐싱해 디스크 IO를 최소화 하여 DB 성능을 향상시키기 위해 존재하는 메모리 영역임.
쿼리 실행중 디스크 IO를 일으키는 데이터를 캐싱하여 반복적인 디스크 IO를 피할 수 있음.
DB시스템의 IO지연이 발생하면 인덱스나 쿼리 튜닝으로 쿼리의 성능이 향상될 수 있는디,
단순히 쿼리의 문제가 아니라면 어떻게 이 문제를 해결하나?
그거슨 바로 Shared Buffer의 동작 원리를 이해하면 근본적인 해결 방법을 제시할 수 있음!
Shared Buffer 구성 요소
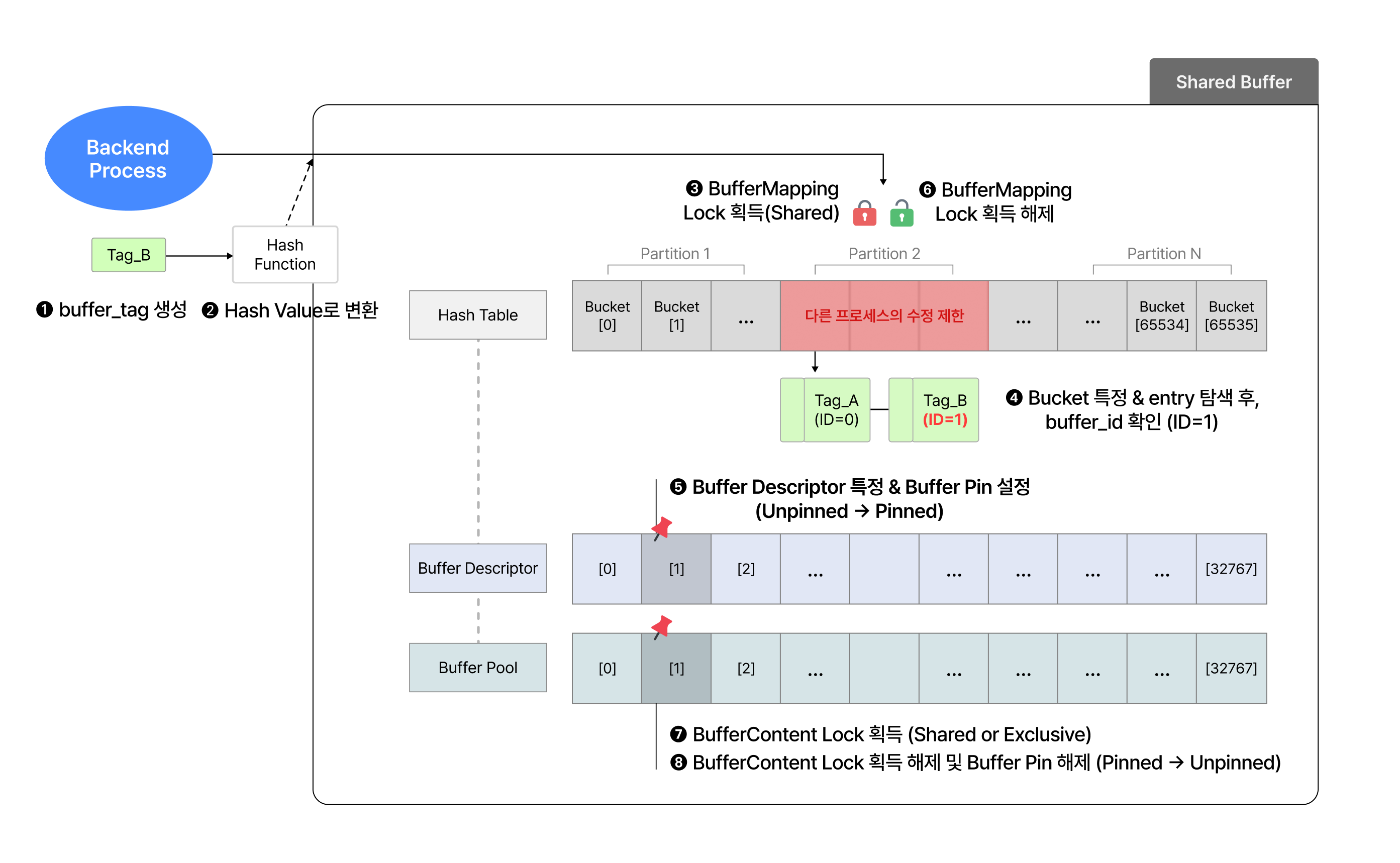
Shared Buffer의 가장 큰 목적은 디스크IO를 최소화해 데이터에 더 빠르게 접근하는 것!
원하는 데이터가 Shared Buffer에 없으면, 디스크에서 필요한 데이터를 버퍼로 읽어서 처리함.
이후 동일한 데이터 페이지에 대해 읽거나 쓰기에 대한 요청이 있을 때, 디스크 IO를 발생시키지 않고 Shared Buffer에서 데이터를 빠르게 처리할 수 있음.
Shared Buffer의 4가지 구성요소

- 해시함수 (Hash Function)
- Backend 프로세스에서 요청한 데이터 즉, 버퍼 태그는 해시 함수를 통해 해시 테이블에 빠르게 접근할 수 있음. 여기서 버퍼 태그는 해시의 입력키(hash key)값이 되고, 이 키 값을 입력해 얻은 결과값이 해시값(hash value)이 됨.
- 해시 테이블(Hash Table)
- 해시 테이블을 사용하면 Backend프로세스가 요청한 데이터 페이지가 메모리의 어느 위치에 존재하는지 빠르게 찾을 수 있음. 원하는 페이지가 메모리에 존재하지 않는다면, 디스크로부터 데이터를 읽어 해시 테이블과 페이지를 매핑시킴.
- 버퍼 디스크립터 (Buffer Descripter)
- 데이터 페이지에 대한 메타 정보를 저장하고 관리함. 각 버퍼의 현재 상태를 추적하여 데이터 페이지가 디스크와 동기화 여부를 결정함.
- 버퍼 풀 (Buffer Pool)
- 데이터가 실제 저장되는 공간으로 디스크의 데이터를 로드한 후 버퍼 풀 영역에서 저장하고 관리함.
- Shared Buffer의 대부분은 버퍼 풀이 차지하고 있고 자주 사용되는 데이터 페이지는 메모리에서 오랫동안 상주시키고 그렇지 않다면 페이지는 교체되어 한정된 메모리 공간을 효율적으로 사용함.
1. Hash Function
해시함수는 가변 길이의 데이터를 고정 길이의 데이터로 변환하는 함수!
해시 함수에 가변 길이의 해시 키값을 입력하면 고정 길이의 해시값을 출력함.
이 해시값은 해시 테이블에 인덱스로 사용되어 버퍼 풀에서 데이터 페이지를 빠르게 검색할 수 있게 함.
2. Hash Table
해시 테이블은 해시 함수를 이용하여 Shared Buffer에 저장된 데이터 페이지를 빠르게 검색할 수 있도록 설계된 자료 구조임.
Shared Buffer는 모든 프로세스가 공용으로 사용하는 리소스이기 때문에 많은 프로세스들이 동시에 리소스를 사용하게 됨. 따라서, 다른 프로세스에 의해 의도하지 핞게 데이터가 변경되어 데이터의 정합성에 문제가 발생할 수 있음.
→ 그래서 이러한 공유 리소스는 LW (Light Weight) 락에 의해 보호됨!
LW락은 동시 접근성을 제어하기 위해 사용되는 낮은 수준의 락 메커니즘으로 시스템 리소스에 대해 잠금과 해제를 빠르고 효율적으로 지원함. Backend 프로세스는 공용 리소스를 사용하기 위해 반드시 LW락을 획득해야 함!
아무튼 Shared Buffer의 효율성을 높이기 위해 해시 테이블을 여러개의 버퍼 파티션으로 나눠 구성하고,
(why? LW락 하나가 해시 테이블 전체를 관리하면 동시에 많은 사용자가 접근할 때, 대기시간이 발생해서, 그래서 여러개의 버퍼 파티션으로 나누고 각 파티션마다 LW락을 할당해 대기시간을 줄임!)
→ 프로세스 사이에서 경합을 줄여줘 메모리와 CPU자원을 효율적으로 사용 가능!
버퍼 파티션은 다시 여러개의 해시 세그먼트로 나눠짐! 해시 세그먼트는 해시 테이블의 데이터를 여러개의 세그먼트로 나눠 저장하고, 각 세그먼트는 독립적으로 해시 테이블을 관리함.
해시테이블의 구성은 버킷 즉 배열임.
해시 버킷은(키, 값) 형태인 키와 값이 쌍으로 매칭되어 저장되는 구조고 해시키를 입력해 해시 함수에서 얻은 해시 값으로 인덱스를 사용하는 구조
근데 여기서 서로 다른 입력값에 동일한 해시 값이 나올 수 있는데 이를 해시 충돌이라고 함!
해시 충돌이 발생하면 버킷과 엘리먼트를 각각 연결하지 못하고 엘리먼트가 서로 연결 리스트 로 연결됨.
이것을 Chaining이라 함.
해시 충돌이 많이 발생하면 해시 테이블에 대한 탐색속도는 저하되기 때문에,.. 가능한 회피하려면 해시 테이블을 하나의 큰 세그먼트로 관리하기보다는 여러개의 논리적인 세그먼트로 분할해서 관리한다..
해시 세그먼트의 장점은 뭐가 있냐
- 데이터를 분할 저장해서 해시 충돌을 줄일 수 있음 → 데이터 검색 성능 향상
- 각 독립적으로 데이터를 관리해서 페이지 교체 알고리즘의 효율성을 높여 전체 시스템의 성능을 향상시킬 수 있음.
- 메모리를 독립적으로 사용할 수 있어 불필요한 메모리낭비를 줄일 수 있음.
해시 테이블의 해시 버킷은 해시 엘리먼트로 구성되어 있는데 여기에 실질적인 데이터들이 저장되어 있음 그게 뭐냐면,,
Hash Element
해시 엘리먼트를 해시 엔트리라고도 하는데, 해시 테이블에서 키를 식별하고 매핑 된 값을 저장함.
해시 테이블의 버킷은 여러개의 해시 엘리먼트를 저장할 수 있음.
해시 엘리먼트는 DB 시작시점에 일정 개수만큼 할당되었다가 요청이 발생하면 다시 할당됨.
그럼 뭐가 있냐?
Hash Value: 해시함수에 의해 생성된 결과값 (이 값은 해시 테이블에서 교유한 식별값으로 사용)Buffer ID: 버퍼 풀에서 특정 버퍼를 식별하는 인덱스로, 데이터 페이지가 존재하는 배열의 위치를 가르킴Buffer Tag: 클러스터 DB에서 Shared Buffer에 캐시 된 데이터 페이지를 식별할 수 있는 정보를 저장함.- RelFileNode(rnode) : DB의 파일의 위치를 나타냄
spcNode: 데이터 페이지가 속한 테이블스페이스를 식별함.dbNode: 데이터 페이지가 속한 DB를 식별함.relNode: 데이터 페이지가 속한 테이블이나 인덱스를 식별함
- ForkNumber (forkNum) : 테이블이나 인덱스에 속한 특정 포크를 식별함.
MAIN_FORKNUM: 메인 데이터 포크로 숫자 0으로 표현FSM_FORKNUM: 여유공간 맵 포크로 숫자 1로 표현VM_FORKNUM **:** 가시성 맵 포크로 숫자 2로 표현
- BlockNumber (blockNum) : 테이블이나 인덱스에서 특정 데이터 블록을 식별할 수 있는 데이터 블록 번호
- RelFileNode(rnode) : DB의 파일의 위치를 나타냄
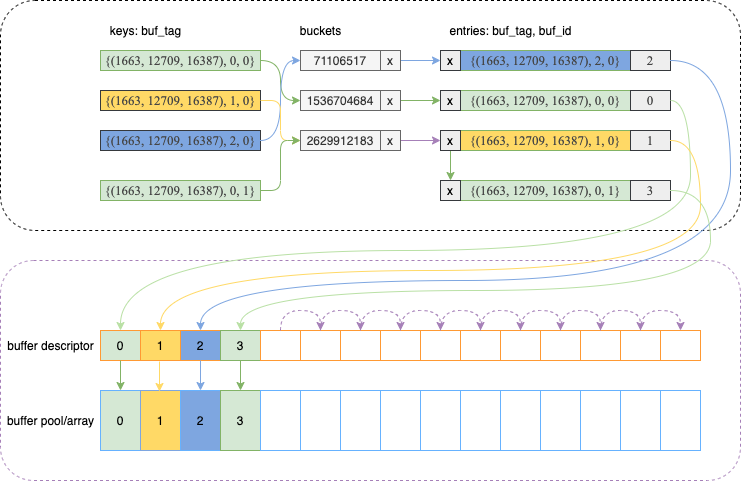
예를들어 이미지 상 [(1663, 12709, 16387), 0, 0] 이면 1663은 테이블스페이즈 OID, 12709는 DB OID, 16387은 테이블 OID, 그 다음의 포크의 유형으로 0이니 메인 포크, 마지막 영역의 0은 데이터 파일에서 페이지 위치를 나타냄. 이 태그가 키값이 되어 해시 함수에 입력값으로 들어가고 보면 1536704684(버킷)으로 계산된 걸 알 수 있음. 그리고 이 값에 해당하는 해시 버킷의 위치를 찾음. → 그 버킷의 연결된 해시 엘리먼트의 Buffer_id는 0이므로, 이는 데이터가 저장된 Buffer pool의 위치가 0번째 배열이라는 뜻!!!
고렇다면 이 버퍼 태그는 언제 생성되는 걸까.
버퍼 태그의 저장된 데이터의 주요 정보는 메모리에 존재하는 데이터 페이지를 찾는 것으므로,
버퍼 태그의 생성은 Backend 프로세스에서 요청한 데이터 페이지에 접근하거나 데이터 페이지가 변경이 필요한 시점에 생성됨. 즉, 순서가
- Backend 프로세스가 쿼리를 수행
- 쿼리가 수행 중 특정 데이터 페이지에 접근 요청을 함.
- 요청에 의해 데이터 페이지에 대한 버퍼 태그를 생성함.
- 버퍼 태그를 이용해 Shared Buffer에서 데이터 페이지를 찾거나 존재하지 않으면 디스크로부터 Load함.
그럼 이 내용을 바탕으로 시뮬레이션을 돌려봅시다.
데이터 입력 시
- backend 프로세스에서 insert 쿼리 (”ABC”)를 수행해 데이터 입력
- 버퍼 태그를 생성하고, 해시 함수를 수행해서 해시값(”123”)을 얻음!
- 해시값(”123”)은 해시 테이블의 특정 버킷( [3] ) 에 매핑시킴.
- 버킷[3]에 해당하는 페이지에 (해시값:123, 버퍼태그, 버퍼 풀 ID: 7) 엘리먼트를 저장함.
- 해시 충돌이 발생했다면, 동일 버킷 내에서 체이닝으로 데이터를 연결해서 저장.
- 버퍼 풀(7)에 데이터 페이지를 Load후에 데이터(” ABC”)를 입력함!
입력한 데이터 검색 시
- Backend 프로세스에서 조회 쿼리 (’ABC”)를 수행함.
- 요청한 쿼리의 버퍼 태그를 생성하고, 해시함수를 수행해 해시값(”123”)을 얻음
- “123”에 해당하는 해시 테이블에 버킷( [3] )을 찾음!
- 해당 버킷에서 데이터를 검색해 해시값이 “123”인 엘리먼트를 찾음
- 엘리먼트에 저장된 메타 정보를 이용해 버퍼 풀 ID (7)에 해당 데이터를 읽어옴
- 요청한 데이터 (”ABC”)를 backend프로세스에 전달
분량이슈로 다음 포스팅에 버퍼 디스크립터, 버퍼풀을 다뤄보자
댓글남기기