PostgreSQL Physical Structure (directory,fork,mainfork,fsm,vm)
[PostgreSQL]PostgreSQL Physical Structure (directory,fork,mainfork,fsm,vm)
PostgreSQL 물리 구조
Postgrsql 물리구조는 디렉토리와 파일, 포크로 구성되어 있음.
초기 설치 시 initdb()를 수행하게 되면 데이터 디렉토리 하위에 DB의 클러스터의 구성요소들이 위치하게 됨.
해당 디렉토리 밑으로 여러가지 파일과 포크, 그리고 또 다른 디렉토리들이 구성됨.
.jpg)
생성된 디렉토리들은 편의의 따라 데이터 디렉토리 영역, 로그 디렉토리 영역, 환경설정 디렉토리 영역, 기타 영역으로 나눌 수 있음.
1. 데이터 디렉토리
데이터 디렉토리 영역은 실제 사용자 데이터가 저장되는 공간으로 Global 디렉토리, Base 디렉토리, pg_tblspc 디렉토리로 구분 됨.
1-1 Global 디렉토리
- 클러스터에 속한 DB들의 공유 정보가 저장되며, 아래와 같은 파일들이 있음.
pg_internal.init,pg_filenode.map: DB 내에 존재하는 오브젝트의 속성 정보, Data 파일과의 Mapping 정보가 포함됨.pg_control: DB운영에 필요한 메타정보가 존재하며pg_controldata 유틸리티를 통해 파일의 내용을 확인할 수 있음.- 기타 숫자 파일들 테이블 스페이스, DB, Role과 같이 여러 DB가 공통으로 사용하는 데이터를 가지고 있는 파일임.
1-2 Base 디렉토리
- 초기 설치시 생성되는 기본 디렉토리 중 하나로, DB 내의 테이블, 인덱스, 함수와 같은 오브젝트가 실제로 저장되는 공간이며, 저장 경로는
$PGDATA/base/{database_OID}/{object_id}순으로 구성됨. - Base 디렉토리 하위에는 DB OID를 이름으로 갖는 디렉토리들이 존재하며, 각각의 DB 디렉토리에 실제 오브젝트 관련 파일들이 위치하게 됨
1-3 pg_tblspc 디렉토리
- 사용자 정의 테이블 스페이스 정보를 저장하는 공간.
- 테이블스페이스를 생성하면 해당 디렉토리 경로에 심볼릭 링크를 통해 연결됨.
2. 로그 디렉토리
2-1 pg_wal
- 장애 발생 시 복구 역할을 수행하는 WAL파일을 저장하는 곳이며, 추가적으로 Replication 구현을 위해 사용됨.
2-2 Log
- DB 운영중 발생하는 데드 락, Vacuum 수행 결과 등 특이사항을 기록하는 공간
3. 환경설정 디렉토리
3-1 pg_version
- DB 버전 정보 표시. 파일 안 기술된 내용과 엔진 버전이 동일해야지만 DB 기동 가능
3-2 pg_hba.conf
- 인증시스템 관련 정보를 담고 있으며 DB에 접속하는 호스트나 호스트의 데이터 전송방식, 암호화 전송박식에 대한 설정을 할 수 있음.
3-3 postgersql.conf
- DB 환경설정 파일
3-4 postgresql.auto.conf
- 사용자 수정이 불가능하며 Alter System 명령어를 통해 변경된 내용들이 저장되는 파일
3-5 postmaster.pid postmaster
- 프로세스의 PID, Data Path, 시작 시간 및 포트 정보를 저장하며 기동중에만 존재함.
4. Fork
postgresql은 물리적 파일을 포크라고 하며 데이터를 여러 포크로 분할하여 데이터 저장 및 검색의 다양한 측면을 관리하고 최적화함.
포크는 데이터 저장과 효율성을 높이기 위해 여러가지 유형으로 구분되어 지는데, 테이블이 생성되면 해당 테이블에 대해 3개의 파일이 존재하게 됨.
- 메인 포크 (main fork) : 주요 데이터가 저장되며 테이블 OID 명으로 파일 생성됨.
- 여유 공간 맵 (free space map) : 메인 포크내의 여유 공간을 관리하기 위한 파일이 생성됨.
- 가시성 맵 ( visible map) : 메인포크의 어느 페이지에 모든 활성 트랜잭션에서 볼 수 있는 튜플의 포함여부를 기록하는 파일이 생성됨.
OID (object identifier)
postgresql은 OID Types를 사용하여 내부에 존재하는 모든 오브젝트들을 구분하고 관리함.
OID는 DB에 내부 객체가 생성될 때마다 자동으로 부여되며 사용자가 테이블을 생성하게 되면 OID와 파일명이 동일하게 생성됨.
---테이블 생성
CREATE TABLE tab_OID(id integer);
---테이블 OID 조회
SELECT OID, relname FROM pg_class WHERE relname = 'tab_OID'
4-1. Main Fork (메인 포크)
메인포크는 테이블이나 인덱스의 행과 같은 실제 데이터가 저장되는 파일 시스템을 의미함.
초기상태는 단일파일로 생성되고, 시간이 지나며 1GB까지 증가하면서 해당 포크에 다른 파일이 생성됨.
이것을 세그먼트라 하며, 이 세그먼트가 계속해서 증가하면 세그먼트에 시퀀스 번호가 할당됨.
테이블과 인덱스를 생성하게 되면 메인 포크의 파일 이름은 OID이며 pg_class 테이블에 존재하는 Relfilenode 컬럼값과 동일함.
하지만 파일에 Vacuum Full, Truncate, Reindex 등과 같이 전체 데이터를 변경하는 작업이 수행되면 OID명은 유지되지만, pg_class테이블에 Relfilenode컬럼 값은 변경됨.
따라서 메인 포크 파일의 이름도 Relfilenode컬럼값으로 변경됨
4-2. Free Space Map (여유공간맵)
데이터가 변경되면 처리되는 과정에서 데이터 페이지에 여유 공간이 생기게됨.
FSM(free space map)은 이 여유 공간 정보를 저장해서 새로운 데이터가 테이블에 입력될 때 기존 데이터 페이지에 적절한 크기의 여유 공간을 찾는 역할을 함.
FSM파일명은 pg_class 테이블에 해당하는 Relfilenode값에 “_fsm”형태의 접미사가 붙음.
(ex. 5678_fsm)
FSM의 사용 목적은?
- 디스크 공간의 낭비를 줄이고 데이터 페이지 공간을 최적화 할 수 있음.
- 데이터 입력 시 기존 페이지의 여유공간을 빠르게 탐색할 수 있음.
FSM의 논리 구조는 어떻게 되냐. FSM은 다수의 FSM페이지로 구성되어 있고 모두 트리 형태로 구성되어 있음.
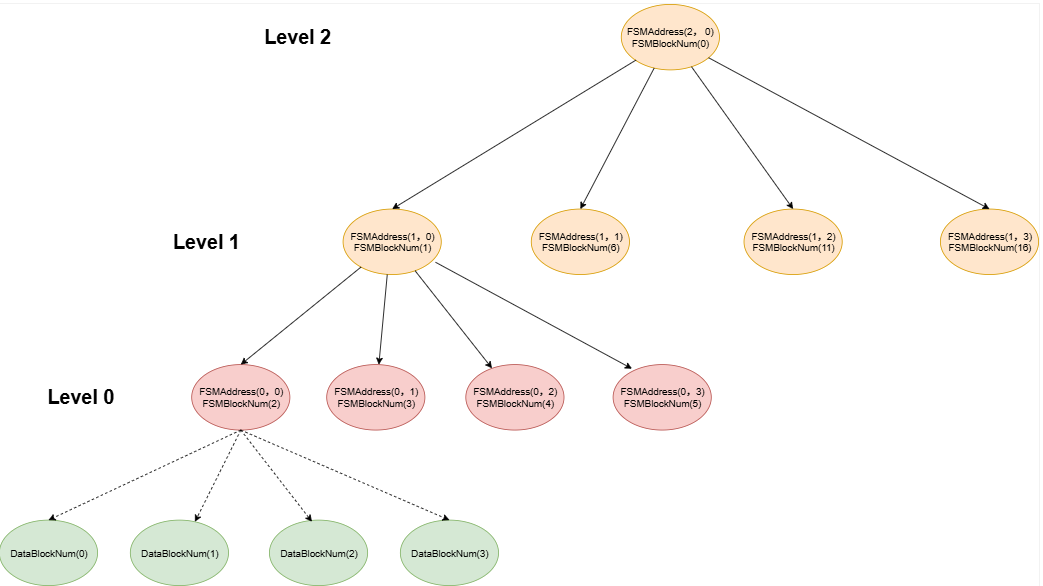
상위에서 하위로 탐색하면 원하는 크기의 페이지 공간을 빠르게 찾을 수 있음.
- FSM파일은 다수의 FSM페이지들로 구성되어 있다~
- FSM페이지는 배열형태의 이진 트리로 구성되어 있으며 일반적으로 3~4개의 Level을 가짐.
- 각 페이지의 리프 노드는 테이블의 페이지를 나타내거나 하위 FSM 페이지의 루트값을 가짐.
- FSM 페이지의 리프가 아닌 노드는 자식 노드의 최댓값을 가짐.
- 최하위 레벨의 해당하는 FSM페이지는 실제 사용 가능한 공간에 대한 정보를 가지고 있음!!!
FSM의 물리적인 구조는 배열을 사용하여 데이터 페이지의 여유 공간 정보를 저장하고 관리하는데,
이 배열 구조는 데이터 페이지의 각 블록에 대한 정보를 포함하며, 이를 통해 빠르게 여유공간을 검색 가능
동작방식은..
페이지 할당- 새로운 데이터가 입력되면 적절한 여유 공간을 가진 페이지를 찾음.
- 적절한 페이지가 존재하면 그 페이지에 데이터를 입력!
페이지 변경- 데이터가 변경되거나 삭제되면, 페이지에 여유 공간이 생기게 되어 FSM리스트에 해당 페이지에 대한 여유공간 정보를 저장함.
Vacuum 실행- AutoVacuum 프로세스나 Vacuum명령어를 실행해 테이블에 사용되지 않는 공간을 회수하고 FSM정보를 변경함
그래서 어떤 테이블에 delete나 update를 수행하여 Dead 튜플이 발생하고, 이때 Vacuum이 수행되면 Dead튜플은 삭제되고 이 공간은 여유 공간으로 FSM에 등록하게 됨! 이 후 새로운 데이터가 입력되면 FSM을 이용해 사용하고 있는 기존 페이지에 여유공간을 검색하게 됨. 기존 페이지에 새로운 데이터를 저장할 수 있는 여유 공간이 있다고 판단되면 검색된 여유 공간에 데이터 저장.
페이지마다 FSM에 등록된 여유 공간은 pg_freespacemap 익스텐션을 통해 조회 할 수 있당
4-3. Visible Map (가시성 맵)
가시성맵(VM)은 활성 트랜잭션들이 페이지 내의 모든 튜플의 가시성 여부를 추적하기 위해 사용됨.
VM을 통해 Vacuum 및 인덱스 스캔을 최적화 할 수 있음!
VM파일 이름은 Relfilenode 값 뒤에 “_vm”이라는 접미사가 붙고 별도 파일 형태로 저장됨.
(ex. “5678_vm”)
VM은 각 테이블에 대해 별도로 존재하며 두 개의 비트값을 가진 비트맵 배열로 구성되어 있음.
비트맵은 0과1로 표현되는 메타 정보 파일이며 튜플의 상태 정보를 축약해서 저장함.
왜 비트로 쓰냐 하면, Vacuum작업에 대해 시간을 단축하고 불필요한 작업을 수행하지 않아 Vacuum 성능을 향상시키기 위함!
즉,
- 테이블에는 VM파일이 존재하지만, 인덱스에는 존재하지 않는다.
- 데이터를 조회할 때 가장 먼저 테이블의 VM정보를 확인한다.
- Vacuum이 필요 없는 페이지는 skip하여 Vacuum작업을 최소화 한다.
VM은 하나의 페이지에 두 개의 비트값을 별도로 가지고 있는데 첫번째는 all_visible이고, 두 번째 비트는 all_frozen임.
ALL_VISIBLE: 페이지의 visible 상태를 비트 정보로 표시함.- 비트가 1(true)일경우 : 페이지의 모든 튜플이 모든 트랜잭션에서 가시성이 보장되며 dead튜플이 없는 상태를 의미함.
- 쿼리 수행 시 테이블의 모든 페이지의 VM비트 정보가 all_visible= 1 일 경우 가시성을 보장하여 테이블을 스캔하지 않고 index only scan만으로 조회 결과를 반환할 수 있음.
- 비트가 0(false)일 경우 :페이지의 모든 튜플 또는 일부 튜플에 대해 Vacuum이 정리할 튜플이 있는 상태. 즉, dead튜플이 존재한다는 의미!
ALL_FROZEN: 페이지의 FROZEN상태를 비트 정보토 표시함.- 비트가 1(true)일 경우 : all_visible =1 인 경우에만 해당하며 페이지의 모든 튜플이 frozen XID가 적용된 상태.
- 비트가 0(false)일 경우 : 페이지의 모든 튜플이나 일부 튜플이 frozen XID가 적용되지 않은 상태
- VM을 통해 all_frozen =1 인 페이지는 all_visible=1인 상태를 의미하며 Vacuum 대상에서 제외됨.
all_visible = 1이면 해당 페이지의 모든 튜플이 모든 트랜잭션에서 Visible한 상태를 의미하고, 0이면 Dead 튜플로 인해 트랜잭션의 스냅샷에 따라 튜플에 대한 가시성을 보장할 수 없는 상태를 의미. 따라서, 트랜잭션에서 참조하지 않는 dead튜플들은 Vacuum에 의해 제거됨! (1 or 0 , x)all_frozen =1이면 튜플이 frozen상태로 첫 번째 비트가 1인 경우에만 해당하고 모든 트랜잭션에서 가시성이 보장되므로 vacuum을 수행할 필요가 없는 상태를 의미함. (1,1)
그래서 VM정보 비트는 Vacuum 수행 및 데이터 변경에 따라 상태값이 변경됨.
- 테이블을 생성 후 데이터가 입력되면 VM상태값은 (0,0)임.
- Vacuum 수행 시 VM 상태 값은 (1,0) 또는 (1,1)임.
- Vacuum Freeze 옵션으로 수행하면 VM상태값은 항상 (1,1)임.
- delete 나 update가 수행되면 vm상태 값은 항상 (0,0)임.
댓글남기기