Logstash - input, filter, output 플러그인
[ELK Stack]Logstash - input, filter, output 플러그인

로그스태시는 다양한 입력 소스에서 데이터를 수집하고, 필터를 통해 정제한 후, 출력으로 전달하는 데이터 처리 도구.
1. Logstash 파이프라인 개요

Logstash 파이프라인은 입력(input), 필터(filter), 출력(output) 블록으로 구성되며, 각 블록은 여러 플러그인으로 확장 가능하다.
input { ... } # 데이터 수신
filter { ... } # 데이터 변형 및 필터링
output { ... } # 출력 대상으로 전달
1.1 파이프라인 설정 파일 구조 (logstash.conf)
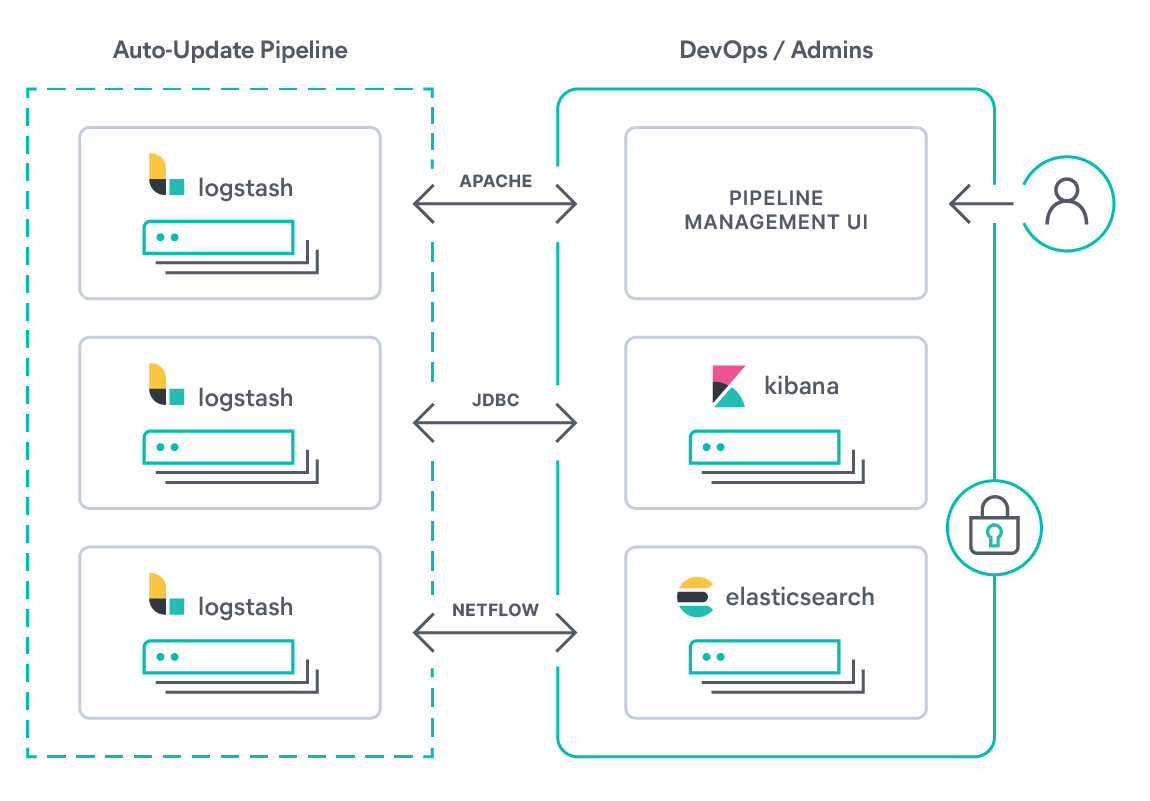
기본 구성: 하나의 .conf 파일에 input, filter, output 블록 정의
- 다중 파이프라인:
pipeline.yml에 여러 파이프라인 별pipeline.id,path.config지정 가능
| 설정 키 | 설명 |
|---|---|
pipeline.id |
파이프라인 식별자 (기본: main) |
path.config |
해당 파이프라인에서 읽을 .conf 파일 경로 리스트 |
pipeline.workers |
병렬 워커 수 (기본: CPU 코어 수) |
pipeline.batch.size |
워커당 한번에 처리할 이벤트 수 (기본: 125) |
pipeline.batch.delay |
이벤트 배치 전 대기 시간(ms, 기본: 50) |
Tip: 워커 수와 배치 크기를 조정해 처리량과 지연 시간을 최적화할 수 있다.
2. 입력(Input) 플러그인
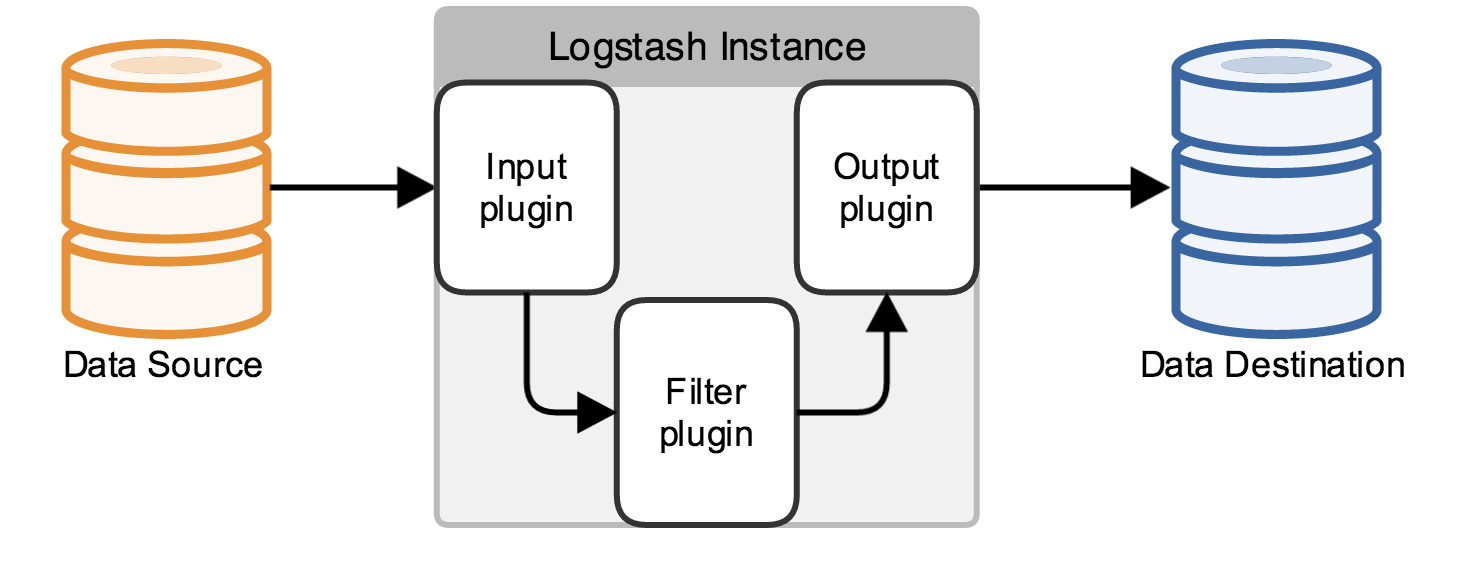
Logstash는 다양한 입력 플러그인을 제공한다. 자주 사용하는 플러그인과 주요 옵션은 다음과 같다.
| 플러그인 이름 | 사용 예시 | 주요 옵션 |
|---|---|---|
file |
파일 모니터링 | path, start_position, sincedb_path, ignore_older |
syslog |
Syslog over UDP/TCP | port, host, type, codec |
kafka |
Kafka 토픽 구독 | bootstrap_servers, topics, group_id, codec, auto_offset_reset |
jdbc |
JDBC DB 쿼리 실행 | jdbc_connection_string, jdbc_user, jdbc_password, statement, schedule |
2.1 file 플러그인
input {
file {
path => "C:/path/to/file.log"
start_position => "beginning"
sincedb_path => "nul"
ignore_older => 604800 # 7일(초)
}
}
sincedb_path: 파일 읽기 상태 저장 경로, 없으면 기본 위치 (~/.sincedb*)ignore_older: 지정 시간(초) 이전 수정된 파일 무시
3. 필터(Filter) 플러그인
3.1 공통 옵션
| 옵션 | 설명 |
|---|---|
id |
플러그인 구분용 식별자 (디버깅 메시지에 사용) |
add_field |
이벤트에 새 필드 추가 |
remove_field |
이벤트에서 특정 필드 제거 |
add_tag |
이벤트에 태그 추가 (tags 배열) |
remove_tag |
이벤트에서 태그 제거 |
enable_metric |
플러그인별 처리량(metrics) 활성화 (기본: true) |
3.2 mutate 플러그인
문자열, 배열, 숫자 등 다양한 필드 조작을 지원.
filter {
mutate {
split => { "message" => " " }
add_field => { "id" => "%{[message][2]}" }
remove_field => ["message"]
uppercase => ["level"]
lowercase => ["host"]
strip => ["path"]
replace => { "status" => "OK" }
}
}
| 옵션 | 설명 |
|---|---|
split |
문자열 필드를 delimiter로 분리하여 배열로 저장 |
join |
배열 필드를 delimiter로 결합하여 문자열로 변환 |
add_field |
지정한 키에 새 필드 추가 |
remove_field |
지정한 키(들) 필드를 이벤트에서 제거 |
uppercase |
대상 필드 값을 대문자로 변환 |
lowercase |
대상 필드 값을 소문자로 변환 |
strip |
대상 필드 값의 앞뒤 공백 제거 |
convert |
데이터 타입 변환 (예: port => "convert" => {"port" => "integer"}) |
rename |
필드명 변경 (예: "rename" => {"old" => "new"}) |
replace |
필드 값을 지정 값으로 교체 |
3.3 dissect 플러그인
고정 포맷 로그에 빠른 성능을 제공. grok보다 경량.
filter {
dissect {
mapping => {
"message" => "[%{timestamp}] [%{id}] %{ip} %{port} [%{level}] - %{msg}."
}
}
}
| 토큰 패턴 | 설명 |
|---|---|
%{field} |
해당 토큰을 field로 저장 |
%{?field} |
토큰 매칭은 하지만 필드로 저장하지 않음 |
%{+field} |
이전 토큰과 이어붙여 하나의 필드로 저장 |
3.4 grok 플러그인
정규표현식 기반 로그 파싱. 유연하지만 파싱 속도는 dissect에 비해 느릴 수 있다.
filter {
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] \[%{DATA:id}\] %{IP:ip} %{NUMBER:port:int} \[%{LOGLEVEL:level}\] - %{GREEDYDATA:msg}" }
pattern_definitions => { "MY_TIMESTAMP" => "%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}" }
}
}
| 패턴 이름 | 예시 매칭 형식 | 설명 |
|---|---|---|
TIMESTAMP_ISO8601 |
2020-01-02T14:17:00Z |
ISO 8601 표준 날짜/시간 |
MY_TIMESTAMP |
2020/01/02 14:17:00 |
사용자 정의 날짜 포맷 |
IP |
192.168.0.1 |
IPv4 주소 |
NUMBER:port:int |
9500 |
숫자 → port 필드(정수) |
LOGLEVEL |
INFO, WARN, ERROR |
로그 레벨 |
DATA |
ID1 |
공백 제외 임의 문자열 |
GREEDYDATA |
전체 남은 문자열 | 남은 모든 텍스트를 캡처 |
3.5 date 플러그인
filter {
date {
match => ["timestamp", "YYYY-MM-dd HH:mm", "yyyy/MM/dd HH:mm:ss"]
target => "@timestamp"
timezone => "UTC"
}
}
- 문자열
timestamp필드를 Logstash의@timestamp로 변환 - 다중 포맷 지원 및 타임존 지정 가능
3.6 drop 플러그인
조건에 따라 이벤트를 파이프라인에서 삭제
filter {
if [level] == "INFO" {
drop { }
}
}
3.7 Mutate vs. Grok 뭘 써야 함?
| 항목 | mutate |
grok |
|---|---|---|
| 핵심 기능 | 문자열/배열 조작, 필드 편집 | 정규표현식 기반 복합 패턴 매칭 |
| 성능 | 매우 빠름 (단순 변환) | 느림 (정규식 처리 비용) |
| 사용 시기 | 단순 필드 변형, 태그/메트릭 조작 | 복잡한 로그 파싱, 필드 추출 |
| 예시 | split, replace, add_field |
로그 전체 구조 파싱 (IP, TIMESTAMP) |
4. 출력(Output) 플러그인
| 플러그인 | 사용 예시 | 주요 옵션 |
|---|---|---|
stdout |
{ stdout { codec => rubydebug } } |
codec |
file |
{ file { path => "output.json" codec => json } } |
path, codec, flush_interval |
elasticsearch |
{ elasticsearch { hosts => ["localhost:9200"] index => "logs-%{+YYYY.MM.dd}" pipeline => "geo" ilm_enabled => true } } |
hosts, index, pipeline, template_name, ilm_enabled |
kafka |
{ kafka { bootstrap_servers => "broker:9092" topic_id => "logs" codec => json } } |
bootstrap_servers, topics, codec, acks |
4.1 Elasticsearch 플러그인 옵션들
| 옵션 | 설명 |
|---|---|
hosts |
Elasticsearch 호스트 리스트 (http://host:port) |
index |
대상 인덱스 이름 (시간 기반 패턴 사용 가능) |
pipeline |
Ingest pipeline ID (Elasticsearch ingest 노드 처리) |
template_name |
인덱스 템플릿 이름 |
template_overwrite |
템플릿 덮어쓰기 여부 |
ilm_enabled |
Index Lifecycle Management 사용 여부 (true/false) |
user/password |
인증 정보 (HTTPS 기본 인증) |
5. Codec 플러그인
Codec은 입출력 플러그인에서 함께 사용하여 데이터 직렬화/역직렬화 방식을 지정.
| Codec 이름 | 설명 |
|---|---|
json |
JSON 포맷으로 인코딩/디코딩 |
plain |
원시 문자열 (기본) |
rubydebug |
Ruby 객체 디버깅 출력 |
json_lines |
한 줄당 하나의 JSON 문서 |
output {
stdout { codec => rubydebug }
}
댓글남기기