Elasticsearch 분석기 - 캐릭터필터,토크나이저,토큰 필터
[ELK Stack]Elasticsearch 분석기 - 캐릭터필터,토크나이저,토큰 필터
1. 분석기란?
Elasticsearch에서 전문 검색(full-text search)을 가능하게 해주는 핵심 기능은 분석기(analyzer) 임. 분석기는 텍스트 데이터를 인덱싱하거나 검색할 때 문자열을 분석해서 토큰(token) 으로 나누고 이를 역인덱스(inverted index) 에 저장함.
역인덱스는 책의 색인(index)처럼 특정 단어가 어느 문서에 등장했는지를 빠르게 찾게 해주는 자료구조임. 이 과정에서 분석기가 어떻게 문자열을 처리하는지가 검색 정확도와 성능에 결정적인 영향을 줌. 특히 자연어 검색, 오타 보정, 추천 시스템 등에서 분석기 설정은 사용자 경험에 큰 영향을 미칠 수 있음.
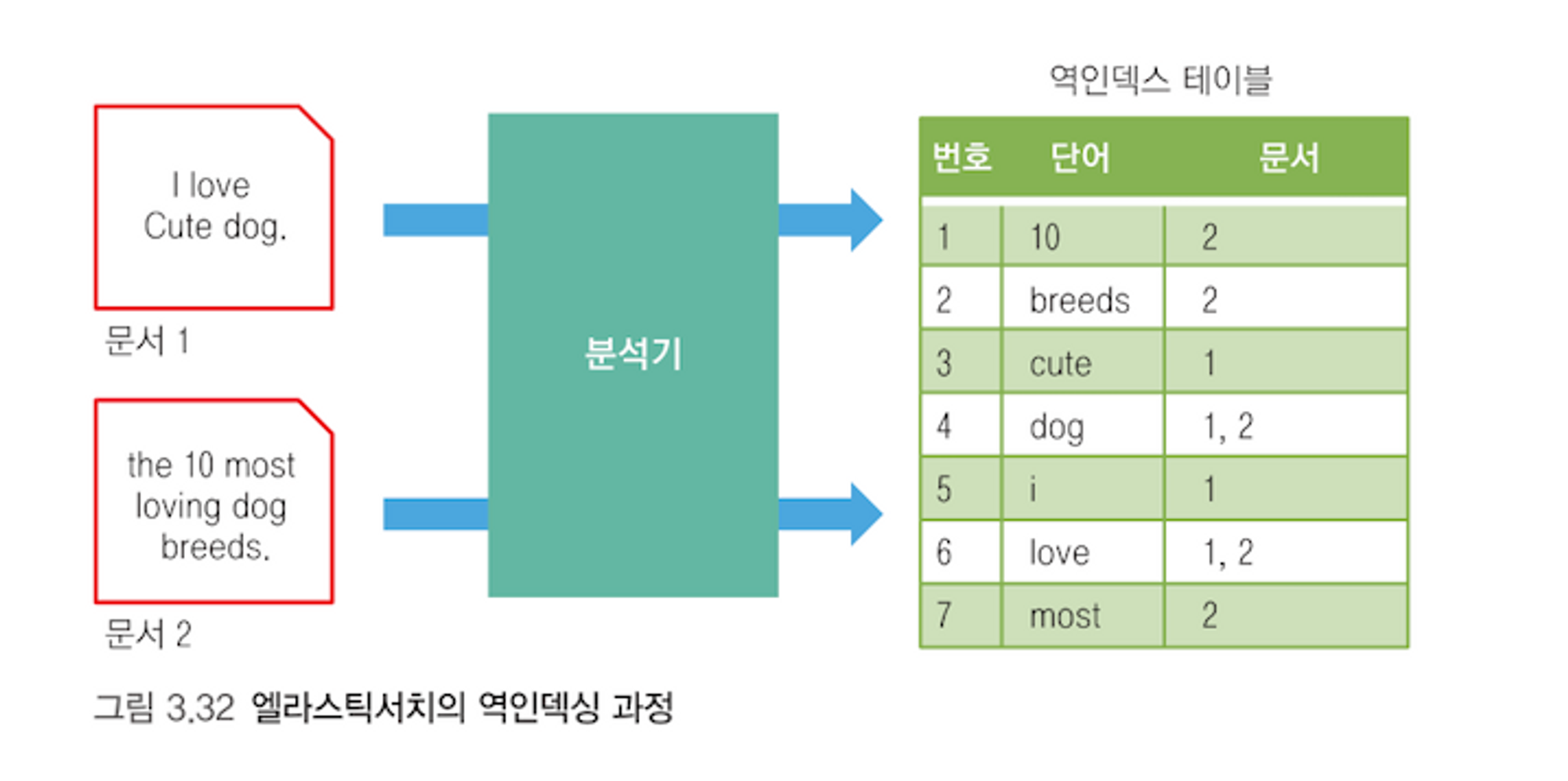
분석기는 기본적으로 다음 세 가지 요소로 구성됨

- 캐릭터 필터 (char_filter): 입력 텍스트에서 HTML 태그 제거, 문자 치환 등 전처리 수행
- 토크나이저 (tokenizer): 텍스트를 토큰 단위로 분리 (공백, 구두점 등 기준)
- 토큰 필터 (token_filter): 소문자화, 불용어 제거, 형태소 분석 등 추가 가공
분석기는 반드시 하나의 토크나이저를 포함해야 하며, 캐릭터 필터와 토큰 필터는 옵션임. 그러나 대부분의 실전에서는 세 요소를 조합해 사용하는 커스텀 분석기를 구성하게 됨.
2. 토큰(token) vs 용어(term)
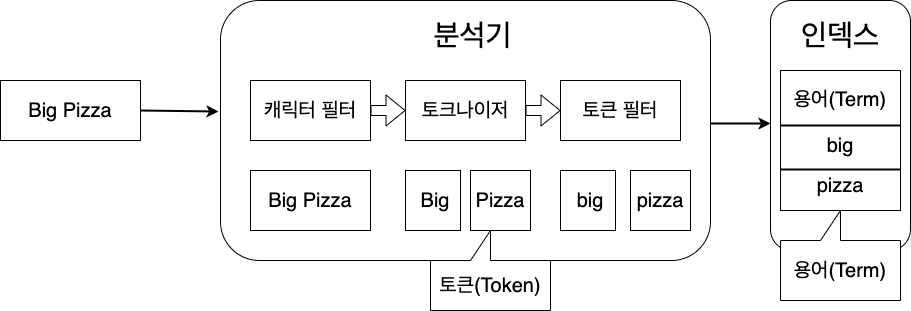
| 구분 | 설명 |
|---|---|
| 토큰(Token) | 분석기 내부에서 임시로 만들어진 중간 단위. 아직 인덱싱되지 않음 |
| 용어(Term) | 토큰 필터를 모두 거쳐, 실제로 인덱싱되어 역인덱스에 저장된 단위 |
예시: "cute dog"라는 텍스트가 있을 때의 분석기 처리 흐름:
- 캐릭터 필터: HTML 태그 제거 등
- 토크나이저:
"cute","dog"두 개의 토큰 생성 - 토큰 필터: 모두 소문자 처리 → 이 상태로 인덱싱됨 → 이것이 용어(term)
즉, 검색에 사용되는 건 term이며, token은 중간 처리 결과임. 이 차이를 명확히 이해해야 분석기 디버깅이나 고급 튜닝 시 혼동이 없음.
3. analyze API로 테스트 가능!
Elasticsearch는 분석기의 동작을 테스트해볼 수 있는 analyze API를 제공함. 이를 통해 분석기 구성 요소별 작동을 사전에 검증 가능함.
POST _analyze
{
"analyzer" : "stop",
"text" : "The 10 most loving dog breads"
}
결과:
"tokens": [
{"token": "most"},
{"token": "loving"},
{"token": "dog"},
{"token": "breads"}
]
The,10은 stop analyzer가 내장한 불용어(stopword) 필터에 의해 제거됨- 분석기 종류에 따라 어떤 토큰이 인덱싱되는지 다르므로, 실제 데이터에 적용 전에는 항상
analyze로 테스트해보는 습관이 중요함
추가적으로 tokenizer, char_filter, filter 항목을 개별 지정하여 커스텀 구성 시 동작 확인도 가능함.
4. 내장 분석기 종류 및 비교
| 분석기 | 특징 및 설명 | 예시 결과 (The 10 most loving dog breads) |
|---|---|---|
standard |
기본 분석기. 영문법 기준의 토크나이저 + 소문자화 + 불용어 제거는 비활성화 | [“the”, “10”, “most”, “loving”, “dog”, “breads”] |
simple |
문자 기준 토큰화. 공백/숫자/기호 무시 | [“the”, “most”, “loving”, “dog”, “breads”] |
whitespace |
공백 기준으로만 토큰화 | [“The”, “10”, “most”, “loving”, “dog”, “breads”] |
stop |
simple + 불용어 제거 | [“most”, “loving”, “dog”, “breads”] |
실무에서는 불용어 제거가 필요한 경우
stop, 한글 형태소 분석이 필요한 경우에는nori같은 커스텀 분석기를 활용함.
5. 토크나이저 종류와 예시
| 토크나이저 | 설명 | 예시 (email: elastic@elk.com) |
|---|---|---|
standard |
기본. 구두점 제거 후 단어 단위로 분리 | [“email”, “elastic”, “elk”, “com”] |
lowercase |
전체를 소문자로 변환 후 분리 | [“email”, “elastic@elk.com”] |
ngram |
N개의 연속된 문자 조각 생성 (ex. 2gram → ab, bc, …) | [“el”, “la”, “as”, “st”, “ti”, “ic”] 등 |
uax_url_email |
URL, 이메일을 토큰으로 유지 | [“email”, “elastic@elk.com”] |
ngram은 자동완성, 철자 교정 기능에서 자주 사용됨. 다만 용량 증가 유의.
6. 토큰 필터 (Token Filter)
| 필터 이름 | 설명 |
|---|---|
lowercase |
모든 문자를 소문자로 변환 |
stop |
불용어 제거 (예: the, a, of 등) |
stemmer |
동사의 원형 추출 (running → run) |
asciifolding |
특수문자 제거 (é → e, ü → u) |
synonym |
동의어를 같은 단어로 처리 (예: car = vehicle) |
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase", "stop"],
"text": "Running across the Fields with élan"
}
→ 결과: running, across, fields, elan → stop 제거 및 소문자 처리
불용어와 소문자 처리 외에도 형태소 분석, 동의어 매핑 등을 활용해 검색 품질을 향상시킬 수 있음
7. 캐릭터 필터 (Char Filter)
캐릭터 필터는 토크나이저 이전 단계에서 문자열을 전처리함. 보통 HTML 태그 제거, 특정 문자 치환 등의 작업을 수행함.
POST _analyze
{
"char_filter": ["html_strip"],
"tokenizer": "standard",
"text": "<b>Hello</b> World Test"
}
→ 결과: hello, world, test
| 캐릭터 필터 | 설명 |
|---|---|
html_strip |
HTML 태그 제거 |
mapping |
지정한 문자들을 치환 |
pattern_replace |
정규식 기반 문자 치환 |
보통 HTML 로그, 웹 크롤링 데이터 분석 시 유용함
8. 커스텀 분석기 구성
커스텀 분석기를 구성하면 복합 조건에 맞는 분석기를 직접 정의할 수 있음.
PUT customer_analyzer
{
"settings": {
"analysis": {
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["lions", "tigers"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
char_filter: HTML 제거tokenizer: 단어 분리filter: 소문자 변환 → 불용어 제거 순서대로 적용됨
필터 적용 순서 중요!
POST customer_analyzer/_analyze
{
"analyzer": "my_analyzer",
"text": "<b>The LIONS are brave.</b>"
}
→ 최종 결과: brave
분석기 순서는
char_filter→tokenizer→token_filter순서로 작동함. 모든 단계를 디버깅하려면 analyze API로 단계별 체크가 필요함.
다음 포스팅에서는 Elasticsearch 검색 쿼리 구조 및 정확도 튜닝 기법 (Boost, Relevance, Minimum Should Match) 에 대해 다룰 예정임.
분석기의 작동 원리를 이해하고 나면, 쿼리 구조와 성능 최적화로 넘어가기 수월해짐.
댓글남기기