BeautifulSoup: 원하는 요소 가져오기 - 책 이름 스크래핑
[BeautifulSoup] 웹 페이지에서 원하는 요소 스크래핑하기
1. 원하는 요소 가져오기 I - 책 이름 모으기 📚
웹 페이지에서 데이터를 스크래핑하는 법을 알아봤으니, 이제 실제 사이트에서 책 이름을 모아보는 연습을 해보겠습니다. 오늘의 타겟은 가상의 책 데이터가 있는 사이트인 Books to Scrape입니다. 이 사이트는 웹 스크래핑 연습용으로 만들어졌죠! 🙌
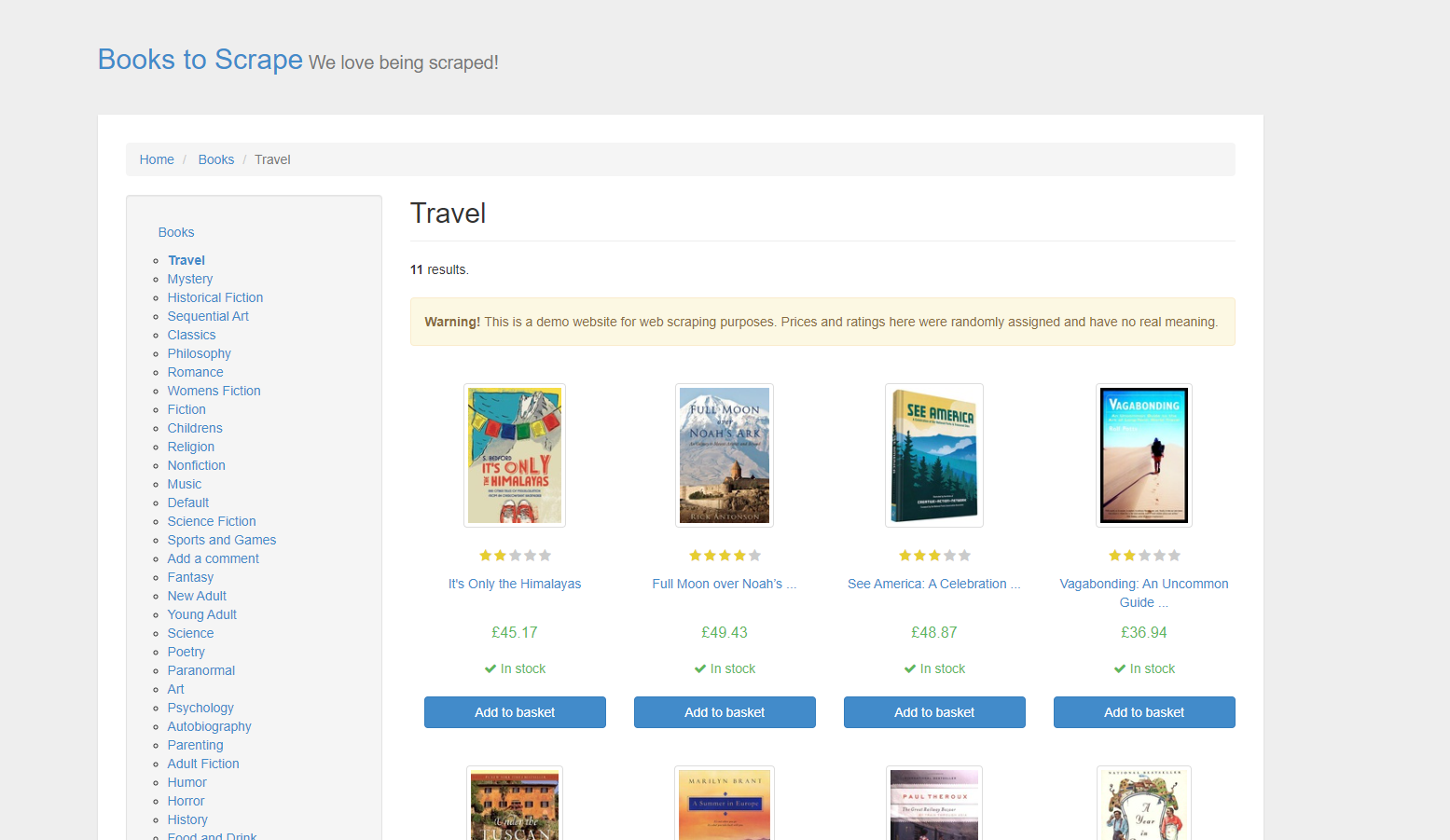
1-1. 준비물
스크래핑을 진행하기 위해 필요한 라이브러리는 이미 익숙하죠.
BeautifulSoup과 requests를 사용합니다.
# 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
1-2. 웹 페이지 요청 및 BeautifulSoup 객체 생성
이제 requests를 사용해 웹 페이지에 요청을 보내고, BeautifulSoup을 사용해 HTML을 parsing 해봅시다.
# 예시 사이트에 요청을 진행하고, 응답을 바탕으로 BeautifulSoup 객체를 만들어봅시다.
res = requests.get("http://books.toscrape.com/catalogue/category/books/travel_2/index.html")
soup = BeautifulSoup(res.text, "html.parser")
1-3. 책 제목 추출하기
책 제목은 <h3> 태그 안에 들어있습니다. 먼저, 첫 번째 책 제목을 찾아봅시다.
# <h3> 태그에 해당하는 요소를 하나 찾아봅시다.
book = soup.find("h3")
book 변수는 첫 번째 <h3> 태그 요소를 가져옵니다. 여기에는 책 제목과 해당 책의 링크가 포함되어 있습니다.
1-4. 모든 책 제목 가져오기
하지만 책 한 권으로는 부족하겠죠? 모든 책 제목을 가져오기 위해 find_all() 메서드를 사용해 <h3> 태그에 해당하는 모든 요소를 찾아봅시다.
# <h3> 태그에 해당하는 요소를 모두 찾아봅시다.
h3_result = soup.find_all("h3")
이제 h3_result 리스트에는 모든 책의 제목이 들어 있는 <h3> 태그들이 저장됩니다. 첫 번째 책의 제목을 확인해볼까요?
# 첫 번째 책 제목을 확인
h3_result[0]
이 결과는 다음과 같습니다:
<h3><a href="../../../its-only-the-himalayas_981/index.html" title="It's Only the Himalayas">It's Only the Himalayas</a></h3>
1-5. 제목만 추출하기
찾아온 데이터는 HTML 요소이므로, 저희가 익숙한 방식대로 title 속성을 추출해 제목만 가져올 수 있습니다. 이제 모든 책 제목을 한꺼번에 가져와봅시다.
# book_list에서 우리가 원하는 제목(title)만 추출해봅시다.
for b in h3_result:
print(b.a["title"])
이 코드를 실행하면, 다음과 같은 결과를 얻게 됩니다:
It's Only the Himalayas
Full Moon over Noah’s Ark: An Odyssey to Mount Ararat and Beyond
See America: A Celebration of Our National Parks & Treasured Sites
Vagabonding: An Uncommon Guide to the Art of Long-Term World Travel
Under the Tuscan Sun
A Summer In Europe
The Great Railway Bazaar
A Year in Provence (Provence #1)
The Road to Little Dribbling: Adventures of an American in Britain (Notes From a Small Island #2)
Neither Here nor There: Travels in Europe
1,000 Places to See Before You Die
1-6. 마무리
자, 이제 여러분은 웹 페이지에서 원하는 정보를 BeautifulSoup을 사용해 손쉽게 가져올 수 있습니다! 이번 실습에서는 <h3> 태그에서 책 제목을 추출했지만, 다른 태그나 속성도 동일한 방식으로 추출 가능합니다. 스크래핑은 연습만이 살 길! 다른 웹 페이지에서도 다양한 데이터를 스크래핑해보세요. 💻
다음 포스팅에서는 좀 더 복잡한 스크래핑 기술을 다뤄보겠습니다. Stay tuned! 😊
댓글남기기